
DeepSeek is a Chinese AI company that has recently rattled the cages in the international LLM business due to its state-of-the-art performance with minimal running costs. Its latest R1 model performs on par with, or even better than, OpenAI’s o1 model in some scenarios.
Why Run DeepSeek Locally?
Both OpenAI and DeepSeek clearly mention in their respective privacy policies that they collect, store and analyze all your data collected via model interactions (voice/text etc.), support requests, and their Partners (but not limited to).
You waive all rights to your private information, allowing these companies to use it as they see fit.
The only way to regain control is to use and run these models on your own hardware. You can even choose to completely disconnect the machine from the internet to ensure there is no phone home.
Isolating your machine from the network is completely optional. The software programs we use for running local LLMs are already open-source and ensure that no network connections occur without your explicit permission.
Until now, we had open-source models like LLAMA3.3, Mixtraletc. which could be run locally, but their performance was not impressive enough to match that of OpenAI, Claude, etc.
However, with DeepSeek’s entry into the market, open-source models are now more capable than ever of performing complex tasks.

These instructions might apply to macOS and Windows (especially when using WSL). Please see the reference section for instructions specific to your platform.
Now, we will go through steps of using DeepSeek locally on our Linux System.
System Requirements
- Preferably Quad Core AMD/Intel CPU — You can run 1/1.5b parameters models quite easily on fairly old CPUs with only iGPU.
- AMD/NVIDIA dGPU — Optional to run medium to large size models.
- 8/16 GB ram DDR3 RAM — more recent ram with high capacity is always recommended.
| Must Have | Good to Have | Optional |
|---|---|---|
| Raspberry Pi | ||
| Intel/AMD Quad core CPU | Recent AMD/Intel CPU | |
| iGPU* | dGPU — AMD/NVIDIA | |
| 64 GB storage** | SSD/NVME | >128 GB NVME |
| 8 GB RAM | 16 GB RAM | >32 GB RAM |
* For smaller models only CPU is used.
** Smaller models use a lot less storage.
Installing OLLAMA
OLLAMA is an open-source tool used to run large language models (LLMs) locally on your computer.
It allows you to install and run a vast number of open-source models directly on your machine.
Run the following command in your terminal to install OLLAMA:
|
|
If you don’t have a dedicated GPU, you may get this warning in the console:

We can safely ignore this message, as we already know without dGPU, we can only run smaller models.
Then go to OLLAMA Website and search deepseek-r1 and open the first search result:
You will see something like this where:
- Model Name
- Available Parameters
- Currently Selected Model (Parameters)
- Command to install the selected model
- Last update of selected model + size of the selected model
- More technical info
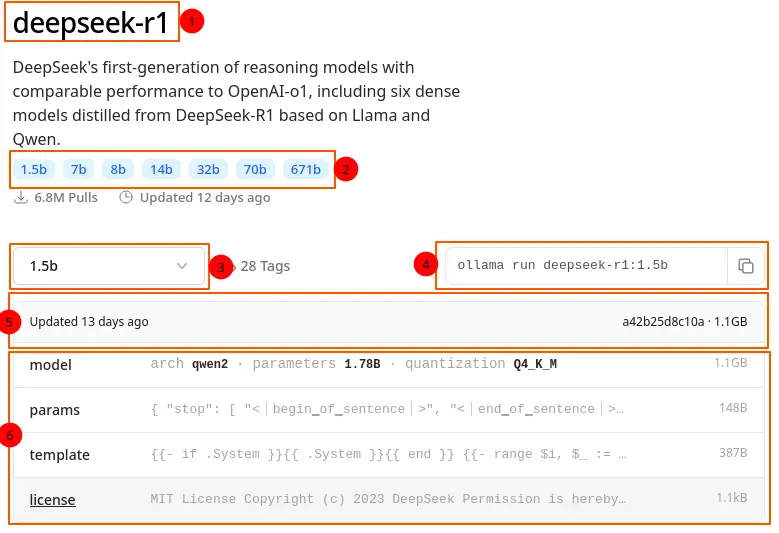
I will install the deepseek-r1:1.5b model:
|
|
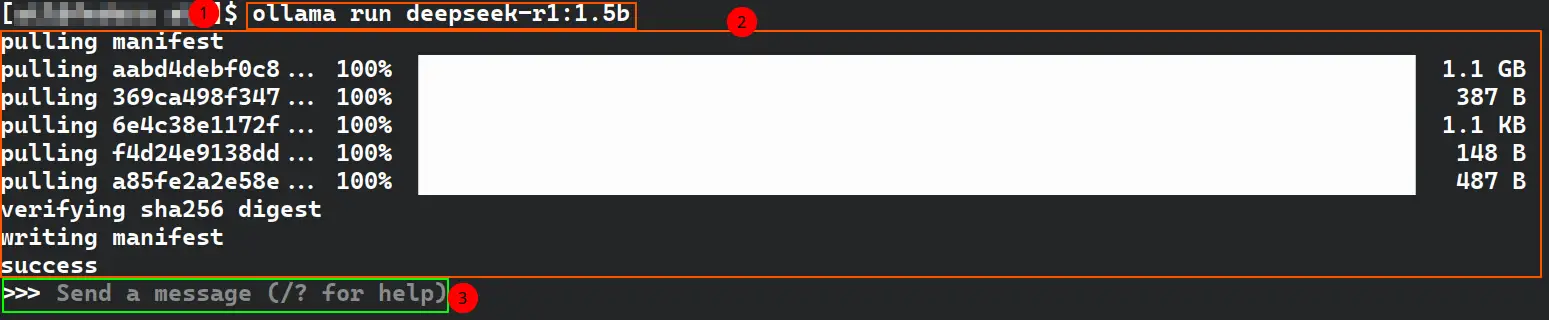
After installation is complete, you will be directly dropped in the model’s chat console, where you can start asking questions right away.
To quit the model:
|
|
Now from the main terminal, you can list the installed models (ollama -h will show all the available commands):
|
|
To run the model again:
|
|
It will only accept the full name of the model like this ollama run deepseek-r1:1.5b.
Now you have access to your own local LLMs, where you own your data and nobody else is snooping on you. You can stop here in the tutorial and start experimenting with other local LLMs in your terminal. Alternatively, keep reading to learn about installing a GUI for your local LLMs.
Open-WebUI: GUI for Local LLMs
Though running LLMs inside a console feels like hacking the mainframe 😇. But for the sake of convenience, we can use Graphical User interface (GUI) too.
Open-WebUI is an open-source user-friendly GUI to interact with your local LLMs (though not limited to local LLMs only).
There are two ways to install it:
- Via PIP (which is a commandline package manager for Python)
- Via Docker (a lightweight container environment)
In this tutorial we will use PIP, which is in most cases already available on UNIX systems.
Run the following command:
|
|
I advise on installing this software inside a Conda environment, which will be separate from your local instance of Python. This way you can keep your home environment clean.
Installing miniconda
Run these commands in your terminal:
|
|
After installation is complete close and re-open your terminal or run the following command to immediately start using conda command in your terminal:
|
|
To initialize conda on all available shells, run this command:
|
|
This will add the Conda initialization config to the available shells (zsh/bash).
Run to turn off auto activation of base Conda environment in your shell (OPTIONAL):
|
|
miniconda Installing Open-WebUI
First create your conda environment:
|
|
Open-WebUI requires Python >= 3.11. So we will create our environment with python 3.11.
Now run this command:
|
|
It will take few mins depending on your network speed, to install the necessary dependencies and main package.
Usage
After installation is complete, execute the following command;
|
|
After fetching necessary package, it will provide you a localhost address, to access your open-webui panel from the browser.
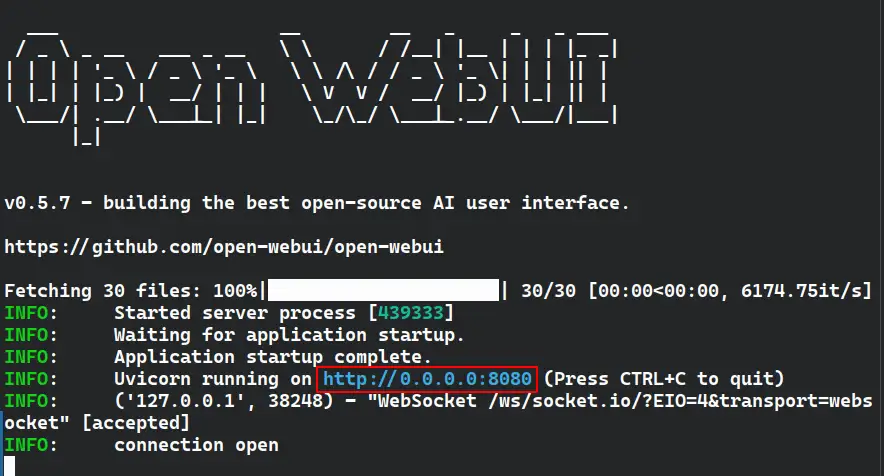
It will ask to create an account, which will act as an admin.
This is a local only account, or if you want to use your local LLMs via internet, when not on your home computer. You will need these credentials to access your LLMs on your computer (You will need to set up port-forwarding/Cloudflare tunnels).
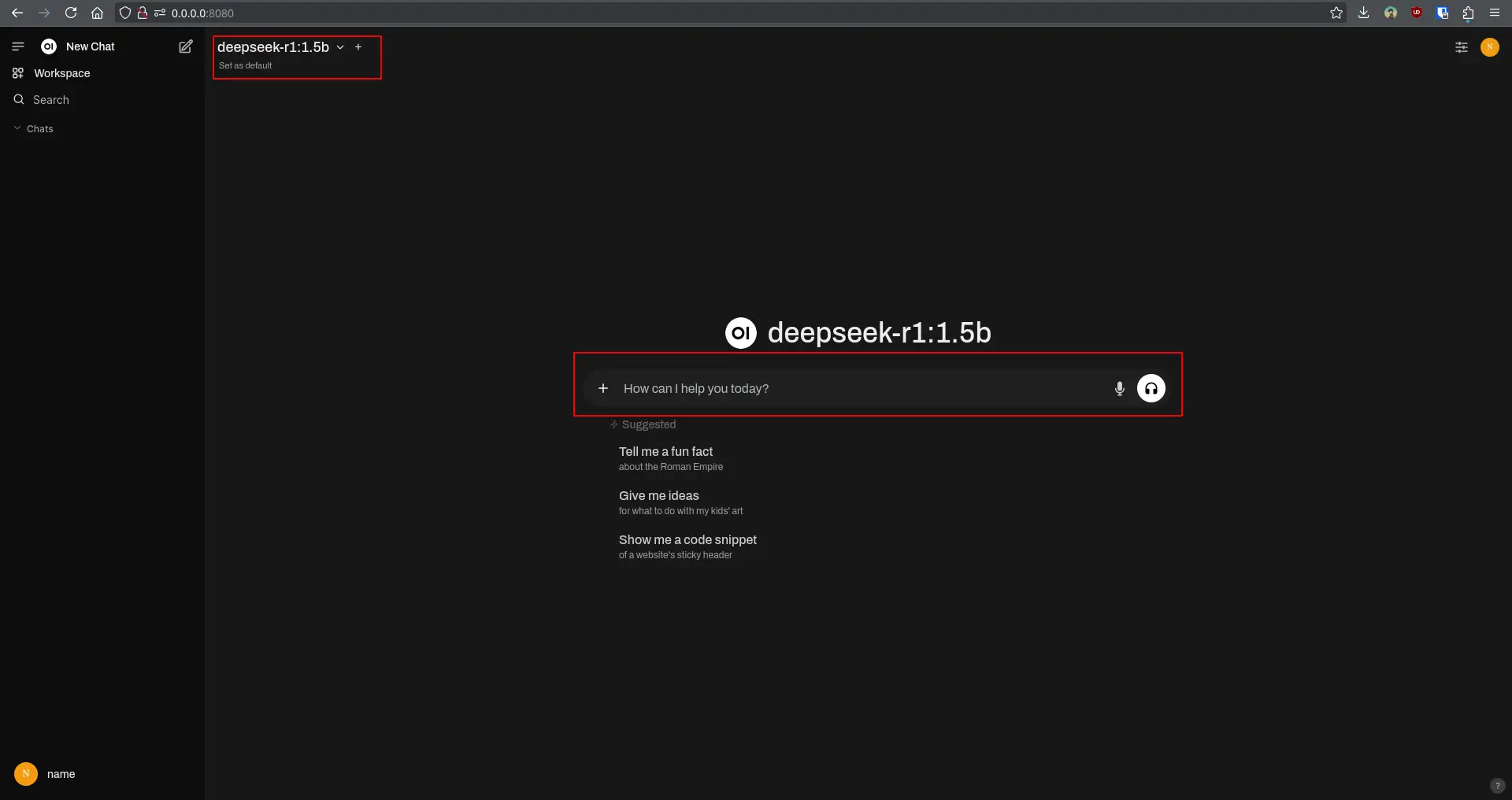
After creating an account, you will be greeted with a screen where you can ask questions, take coding help, or analyze documents, depending on your model.
That’s all for now. Feel free to explore different LLMs and enjoy the benefits of your private AI assistants. If you have any questions or feedback, please leave a comment below!
References
- OLLAMA Download — Follow the download instruction according to your OS.
- OLLAMA Available Models — Choose which model you like to install on your ollama instance.
- How to install Open WebUI — Official Installation instructions via PiP and Docker.
- Miniconda — MiniConda installation docs.
- you NEED to run DeepSeek locally - Linux Guide — TechHut video about OLLAMA and Open-WebUI installation (He uses docker installation method for Open-WebUI).